| title | category | tag | head | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Summary of Common Java Interview Questions (Part 2) |
Java |
|
|
Overview of Java Exception Class Hierarchy:
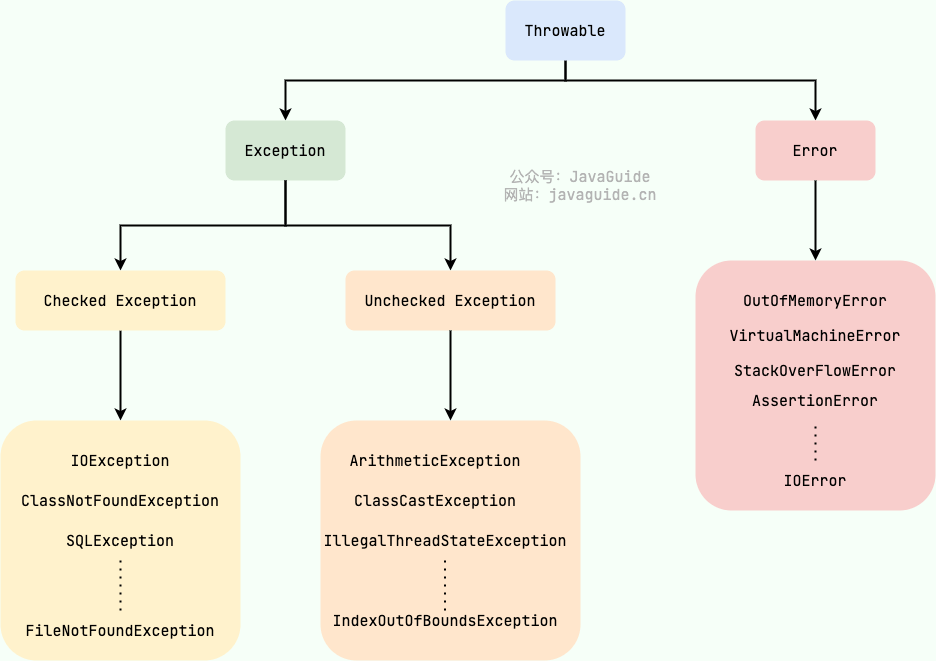
In Java, all exceptions have a common ancestor, the Throwable class in the java.lang package. The Throwable class has two important subclasses:
Exception: Exceptions that can be handled by the program itself and can be caught usingcatch.Exceptioncan be further divided into Checked Exceptions (which must be handled) and Unchecked Exceptions (which can be ignored).Error: Errors that are not usually handled by the program. It is not recommended to catchErrors. Examples include Java Virtual Machine errors (VirtualMachineError), out of memory errors (OutOfMemoryError), and class definition errors (NoClassDefFoundError). When these exceptions occur, the Java Virtual Machine (JVM) generally terminates the thread.
Checked Exception refers to exceptions that are checked at compile-time. If a checked exception is not handled by a catch block or the throws keyword, the code will not compile.
For example, in the following IO operations code:
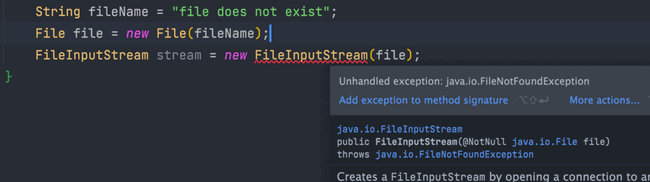
All Exception classes and their subclasses, except for RuntimeException, are considered checked exceptions. Common checked exceptions include IO-related exceptions, ClassNotFoundException, SQLException, etc.
Unchecked Exception refers to exceptions that are not checked at compile-time. Java code can compile normally even if unchecked exceptions are not handled.
RuntimeException and its subclasses are referred to as unchecked exceptions. Common ones (recommended to remember as they will be frequently used in daily development):
NullPointerException(null pointer exception)IllegalArgumentException(argument errors, such as incorrect method parameter types)NumberFormatException(string conversion to number format error, a subclass ofIllegalArgumentException)ArrayIndexOutOfBoundsException(array index out of bounds error)ClassCastException(class cast error)ArithmeticException(arithmetic error)SecurityException(security error, such as insufficient permission)UnsupportedOperationException(unsupported operation error, such as trying to create the same user twice)- ……
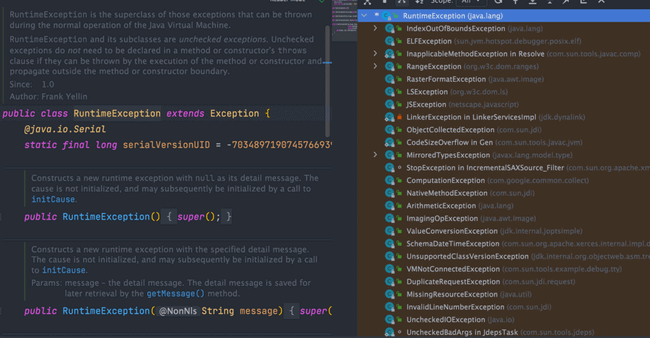
String getMessage(): Returns detailed information about the exception.String toString(): Returns a brief description of the exception.String getLocalizedMessage(): Returns localized information about the exception object. If this method is overridden by a subclass ofThrowable, it can generate localized information. If not overridden, it returns the same information asgetMessage().void printStackTrace(): Prints the exception information encapsulated by theThrowableobject to the console.
tryblock: Used to catch exceptions. It can be followed by zero or morecatchblocks, and if there are no catch blocks, it must be followed by afinallyblock.catchblock: Used to handle the exception caught by the try block.finallyblock: The statements in thefinallyblock are executed regardless of whether an exception was caught or handled. If areturnstatement is encountered in thetryorcatchblocks, thefinallystatements will be executed before the method returns.
Code example:
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
} finally {
System.out.println("Finally");
}Output:
Try to do something
Catch Exception -> RuntimeException
Finally
Note: Do not use return in the finally block! If both the try block and the finally block contain return statements, the one in the try block will be ignored. This is because the return value from the try block is temporarily stored in a local variable, and when the return statement in the finally block is executed, this local variable’s value is replaced by the return value in the finally block.
Code example:
public static void main(String[] args) {
System.out.println(f(2));
}
public static int f(int value) {
try {
return value * value;
} finally {
if (value == 2) {
return 0;
}
}
}Output:
0
Not necessarily! In some cases, the code in the finally block may not be executed.
For example, if the JVM terminates before reaching the finally, the code in the finally block will not be executed.
try {
System.out.println("Try to do something");
throw new RuntimeException("RuntimeException");
} catch (Exception e) {
System.out.println("Catch Exception -> " + e.getMessage());
// Terminate the currently running Java virtual machine
System.exit(1);
} finally {
System.out.println("Finally");
}Output:
Try to do something
Catch Exception -> RuntimeException
Additionally, in the following two special cases, the code in the finally block will also not be executed:
- The thread running the program dies.
- The CPU is shut down.
Related issue: Snailclimb#190.
🧗🏻 Advanced: Analyze the underlying implementation principles of try-catch-finally from the bytecode perspective.
- Applicable scope (definition of resources): Any object that implements
java.lang.AutoCloseableorjava.io.Closeable. - Closing resources and execution order of finally block: In
try-with-resourcesstatements, any catch or finally blocks run after the declared resources have been closed.
"Effective Java" clearly states:
When facing resources that must be closed, we should always prefer to use
try-with-resourcesinstead oftry-finally. The resulting code is neater, clearer, and the exceptions generated are more useful.try-with-resourcesallows us to write code dealing with resources that must be closed more conveniently, something that is virtually impossible withtry-finally.
Resources like InputStream, OutputStream, Scanner, and PrintWriter in Java require us to invoke their close() method to close them manually. Generally, we implement this requirement with try-catch-finally statements as follows:
// Read content from a text file
Scanner scanner = null;
try {
scanner = new Scanner(new File("D://read.txt"));
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (scanner != null) {
scanner.close();
}
}Using the try-with-resources statement introduced in Java 7, we can refactor the above code as follows:
try (Scanner scanner = new Scanner(new File("test.txt"))) {
while (scanner.hasNext()) {
System.out.println(scanner.nextLine());
}
} catch (FileNotFoundException fnfe) {
fnfe.printStackTrace();
}When multiple resources need to be closed, using try-with-resources is also very simple. If you still use try-catch-finally, it may lead to many issues.
By using a semicolon to separate, we can declare multiple resources in the try-with-resources block.
try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
int b;
while ((b = bin.read()) != -1) {
bout.write(b);
}
}
catch (IOException e) {
e.printStackTrace();
}- Do not define exceptions as static variables because this can cause the exception stack information to be messed up. Every time we manually throw an exception, we need to create a new exception object to throw.
- The thrown exception messages must be meaningful.
- It is advisable to throw more specific exceptions. For example, when there is an error converting a string to a number format, the appropriate exception to throw would be
NumberFormatExceptioninstead of its parent classIllegalArgumentException. - Avoid duplicate logging: If sufficient information (including exception type, error message, and stack trace) has already been logged in the place where the exception was caught, then the same error information should not be logged again when rethrowing this exception in business code. Duplicative logging inflates log files and may obscure the actual cause of problems, making tracing and resolving issues harder.
- ……
Java Generics is a new feature introduced in JDK 5. Using generic parameters enhances the readability and stability of code.
The compiler conducts checks on generic parameters, allowing you to specify the type of objects being passed. For example, the line ArrayList<Person> persons = new ArrayList<Person>() indicates that this ArrayList object can only contain Person objects, and passing in other types of objects will result in an error.
ArrayList<E> extends AbstractList<E>Moreover, without generics, the return type of the raw List is Object, which necessitates manual type casting to use the elements, while generics enable automatic type conversion by the compiler.
Generics can generally be used in three ways: Generic Classes, Generic Interfaces, and Generic Methods.
1. Generic Class:
// The T here can be any identifier, commonly used forms are T, E, K, V etc. to represent generics.
// When instantiating a generic class, the specific type of T must be specified.
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}How to instantiate a generic class:
Generic<Integer> genericInteger = new Generic<Integer>(123456);2. Generic Interface:
public interface Generator<T> {
public T method();
}Implementing a generic interface without specifying a type:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}Implementing a generic interface with specified type:
class GeneratorImpl implements Generator<String> {
@Override
public String method() {
return "hello";
}
}3. Generic Method:
public static <E> void printArray(E[] inputArray)
{
for (E element : inputArray) {
System.out.printf("%s ", element);
}
System.out.println();
}Usage:
// Create arrays of different types: Integer, Double, and Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray(intArray);
printArray(stringArray);Note:
public static <E> void printArray(E[] inputArray)is often called a static generic method; in Java, generics are merely placeholders, and must be used after passing the type. The actual type parameters are truly passed when the class is instantiated. Since static methods load before class instantiation, it means that generics in the class have not yet passed the true type parameters. Thus, static generic methods cannot use generics declared on the class; they can only use their own declared<E>.
- Custom interface common return results
CommonResult<T>allows specifying the result data type dynamically based on the parameterT. - Defining an
Excelprocessing classExcelUtil<T>to dynamically specify the data type forExcelexports. - Building collection utility classes (referencing the
sortandbinarySearchmethods inCollections). - ……
For a detailed discussion on Reflection, please check this article Detailed Explanation of Java Reflection Mechanism.
If you have studied the underlying principles of frameworks or written your own frameworks, you must be familiar with the concept of reflection. Reflection is considered the soul of frameworks mainly because it grants us the ability to analyze classes and invoke their methods at runtime. With reflection, you can obtain all properties and methods of any class and invoke these methods and properties.
Reflection allows our code to be more flexible and facilitates the functionality provided by various frameworks.
However, while reflection gives us the ability to analyze operation classes at runtime, it also increases security concerns, such as bypassing the safety checks of generic parameters (which happen at compile-time). Additionally, reflection is generally slower in performance, though this is not a significant issue for frameworks in practice.
Related reading: Java Reflection: Why is it so slow?.
Most of the time, we write business logic code and rarely directly encounter scenarios that utilize reflection. But! This does not imply that reflection is useless. On the contrary, it is precisely because of reflection that you can easily use various frameworks. Frameworks like Spring/Spring Boot, MyBatis, etc., heavily utilize reflection.
These frameworks also extensively use dynamic proxies, and the implementation of dynamic proxies relies on reflection.
For example, the following is an example of JDK dynamic proxy implementation, which uses the reflection class Method to call the specified method.
public class DebugInvocationHandler implements InvocationHandler {
/**
* The real object in the proxy class.
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
System.out.println("after method " + method.getName());
return result;
}
}Additionally, one powerful feature in Java, annotations, is also implemented using reflection.
Why does a class declared as a Spring Bean just require an @Component annotation when using Spring? Why does using an @Value annotation allow you to read values from configuration files? How does this work?
This is all because you can analyze classes based on reflection and obtain class/property/method/parameter annotations. After obtaining annotations, you can perform further processing.
Annotation is a new feature introduced in Java 5, which can be seen as a special type of comment primarily used to modify classes, methods, or variables, providing some information for programs to use at compile time or runtime.
An annotation is essentially a special interface that extends Annotation:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
public interface Override extends Annotation{
}The JDK provides many built-in annotations (such as @Override, @Deprecated), and we can also define custom annotations.
Annotations only take effect once they are interpreted; common interpretation methods include two types:
- Compile-time direct scanning: The compiler scans and processes the corresponding annotations when compiling Java code. For example, if a method uses the
@Overrideannotation, the compiler checks whether the current method overrides the corresponding method in the parent class during compilation. - Runtime processing via reflection: Annotations provided in frameworks (like Spring's
@Value,@Component) are processed using reflection.
For a detailed discussion on SPI, please check this article Detailed Explanation of Java SPI Mechanism.
SPI stands for Service Provider Interface. Literally, it means "an interface for service providers". My understanding is that it is an interface specifically for use by service providers or developers expanding framework functionality.
SPI separates service interfaces from specific service implementations, decoupling service callers from service implementers, thereby enhancing program extensibility and maintainability. Modifying or replacing service implementations does not require changes to callers.
Many frameworks utilize Java's SPI mechanism, such as the Spring framework, database drivers, logging interfaces, and the extension implementations of Dubbo, etc.

What is the difference between SPI and API?
When discussing SPI, one cannot help but mention API (Application Programming Interface). Broadly speaking, both belong to interfaces, and it's easy to confuse the two. The following diagram illustrates this:
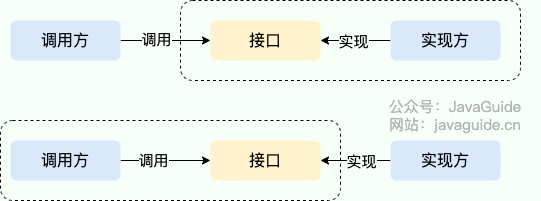
In typical systems, modules communicate through interfaces, so we introduce an "interface" between service callers and service implementers (also known as service providers).
- When the implementer provides an interface and implementation, we can call the implementer's interface to use the capabilities offered by the implementer, which is API. In this case, the interface and implementation are both located in the implementer's package. The caller utilizes the implementer's functions through the interface without needing to care about the specific implementation details.
- When the interface exists on the caller's side, this is SPI. The interface caller determines the interface rules while different vendors implement this interface based on the rules to provide services.
For example, let’s say company H is a tech company that has designed a new chip, and now it requires mass production. Market has several chip manufacturing companies. In this case, as long as company H sets the production standards for this chip (defining the interface standards), these cooperating chip companies (service providers) can deliver their unique chips according to the standards (providing different implementation options, but yielding the same result).
The SPI mechanism greatly enhances the flexibility of interface design, but it does have some disadvantages, such as:
- It requires loading all implementation classes, which prevents on-demand loading and results in lower efficiency.
- When multiple
ServiceLoaderinstances simultaneouslyload, there could be concurrency issues.
For a detailed explanation of serialization and deserialization, please check this article Detailed Explanation of Java Serialization, which includes more comprehensive knowledge points and interview questions.
If we need to persist Java objects, such as saving Java objects to a file or transmitting them over a network, serialization is required.
In simple terms:
- Serialization: The process of converting a data structure or object into a format that can be stored or transmitted, typically a binary byte stream, but can also include formats like JSON and XML.
- Deserialization: The process of converting the data generated during serialization back into the original data structure or object.
In a language like Java, which is object-oriented, we serialize objects (instances of classes). However, in a semi-object-oriented language like C++, struct defines data structure types, whereas class defines object types.
Common scenarios for serialization and deserialization include:
- Objects need to be serialized before being transmitted over the network (e.g., during remote method calls RPC), and deserialized after receiving.
- Objects must be serialized before being stored in files and deserialized when read back from files.
- Objects stored in databases (such as Redis) need serialization before storage and deserialization when retrieved from the caching database.
- Objects need to be serialized before being retained in memory and deserialized when retrieved.
According to Wikipedia, serialization is described as follows:
Serialization in computer science data processing refers to the process of converting a data structure or object state into a format that can be readily stored (for example, in a file, buffer, or sent over a network) to allow for its restoration in the same or different computing environments. The resulting bytes can then be used to produce a replica with the same semantics as the original object. For many complex objects, especially those withmany references, the serialization reconstruction can be challenging. In OOP, object serialization does not encompass the functions associated with the original object. This process is also referred to as object marshaling. The reverse operation of extracting data structures from a series of bytes is called deserialization (also known as unmarshalling, or unmarshal).
In summary: The main purpose of serialization is to transmit objects over a network or to store them in file systems, databases, or memory.
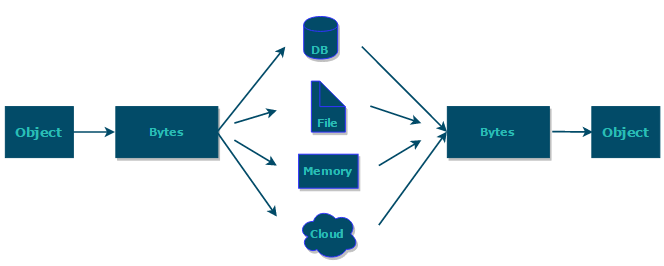
https://www.corejavaguru.com/java/serialization/interview-questions-1
What layer of the TCP/IP model does the serialization protocol correspond to?
We know that both parties in network communication must adopt and comply with the same protocol. The TCP/IP four-layer model looks as follows; which layer does the serialization protocol belong to?
- Application Layer
- Transport Layer
- Network Layer
- Network Interface Layer

As shown above, in the OSI seven-layer protocol model, the presentation layer processes user data from the application layer, converting it to binary streams. Conversely, it transforms binary streams back into user data at the application layer. Doesn’t this directly correspond to serialization and deserialization?
Since the application, presentation, and session layers in the OSI model correspond with the application layer in the TCP/IP model, the serialization protocol is a part of the application layer of the TCP/IP protocol.
For fields that should not be serialized, use the transient keyword.
The transient keyword serves the purpose of preventing the serialization of variables marked with it; when the object is deserialized, the values of the transient variables will not be persisted or restored.
A few additional points about transient:
transientcan only modify variables, not classes or methods.- Variables marked as
transientwill have their values set to their types’ default values upon deserialization. For instance, if it is anint, the result will be0. staticvariables, because they do not belong to any instance (object), will not be serialized regardless of whether or not they are marked astransient.
The serialization method provided by JDK is generally not used due to its low efficiency and security issues. More commonly used serialization protocols include Hessian, Kryo, Protobuf, ProtoStuff, which are all binary-based serialization protocols.
JSON and XML belong to text-based serialization methods. While they are more readable, they generally offer lower performance and are usually not selected.
We rarely or nearly never directly use the serialization method built into JDK, primarily for the following reasons:
- Does not support cross-language calls: It does not support other language-developed services.
- Poor performance: Compared to other serialization frameworks, its performance is lower, primarily because the serialized byte array is large, which increases transmission costs.
- Security issues: Serialization and deserialization themselves do not inherently pose problems. But when the input deserialization data can be controlled by users, an attacker might construct malicious input causing deserialization to produce unintended objects, which may execute arbitrary code during this process. Related reading: Application Security: JAVA Deserialization Vulnerability.
For detailed insights into I/O, please refer to the following articles, which cover more comprehensive knowledge points and interview topics.
IO stands for Input/Output, which refers to the process of inputting data into the computer's memory and outputting it to external storage (like databases, files, or remote hosts). The process of data transmission is akin to water flow, thus termed IO streams. Java's IO streams are divided into input streams and output streams, further classified into byte streams and character streams based on data processing approaches.
Over 40 classes in Java's IO streams are derived from these four abstract class bases:
InputStream/Reader: The base class for all input streams, with the former being byte input streams and the latter being character input streams.OutputStream/Writer: The base class for all output streams, with the former being byte output streams and the latter being character output streams.
The essence of the question is: Regardless of file reading/writing or network sending/receiving, the minimal storage unit of information is byte. Why is the I/O operation divided into byte stream operations and character stream operations?
I believe the reasons are twofold:
- Character streams are produced from byte conversions by the Java Virtual Machine, a process that is rather time-consuming.
- If we are unaware of the encoding type, using byte streams could easily result in garbled text.
Reference answer: Summary of Java IO Design Patterns
Reference answer: Detailed Explanation of Java IO Models
Syntax sugar refers to a special syntax designed in programming languages for the convenience of developers, which does not affect the language’s functionality. The code written using syntax sugar often performs the same function but is simpler, cleaner, and more readable.
For example, the for-each construct in Java is a common syntax sugar that is fundamentally based on standard for loops and iterators.
String[] strs = {"JavaGuide", "Official Account: JavaGuide", "Blog: https://javaguide.cn/"};
for (String s : strs) {
System.out.println(s);
}However, the JVM does not recognize syntax sugar directly; Java syntax sugar must be desugared correctly by the compiler. This means that during the compilation phase, it gets transformed into the basic syntax recognizable by the JVM. This also suggests that the Java compiler, not the JVM, supports syntax sugar. If you look at the source code of com.sun.tools.javac.main.JavaCompiler, you will find that in compile(), there is a step called desugar(), which is responsible for the implementation of desugaring.
The most commonly used syntax sugars in Java include generics, automatic boxing/unboxing, varargs, enums, inner classes, enhanced for loops, try-with-resources syntax, lambda expressions, etc.
For a detailed interpretation of these syntax sugars, please refer to this article Detailed Explanation of Java Syntax Sugar.