| title | category | tag | |
|---|---|---|---|
HashMap Source Code Analysis |
Java |
|
Thanks to changfubai for the contributions to the improvement of this article!
HashMap is primarily used to store key-value pairs. It implements the Map interface based on a hash table and is one of the commonly used Java collections. It is not thread-safe.
HashMap can store null keys and values, but there can only be one null key, while multiple null values are allowed.
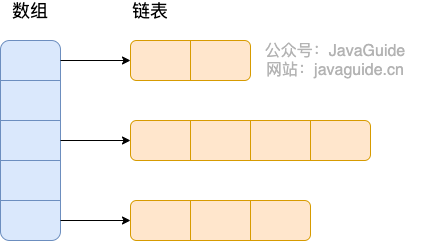
Before JDK 1.8, HashMap was composed of an array and a linked list, where the array was the main structure and the linked list existed primarily to resolve hash collisions (using the "chaining method"). Since JDK 1.8, significant changes have been made in How HashMap resolves hash collisions. When the length of the linked list exceeds the threshold (default is 8), it converts the linked list into a red-black tree before determining what to do next. If the current array length is less than 64, it will first expand the array rather than convert it to a red-black tree, in order to reduce search time.
The default initial size of HashMap is 16. Each time it expands, the capacity is doubled. Additionally, HashMap always uses powers of 2 as the size of its hash table.
Before JDK 1.8, the underlying structure of HashMap was a combination of array and linked list, also referred to as chaining.
HashMap obtains a hash value through the key's hashCode processed by a perturbation function, and then determines the storage position of the current element using the formula (n - 1) & hash (where n refers to the length of the array). If there is an existing element at that position, it checks if that element’s hash value and key are the same as the one being inserted. If they are the same, it directly replaces it. If they are different, it resolves the collision using the chaining method.
The perturbation function refers to the hash method of HashMap. The purpose of using the hash method, or the perturbation function, is to avoid collisions caused by poorly implemented hashCode() methods. In other words, using the perturbation function can reduce collisions.
Source code of the hash method in JDK 1.8 HashMap:
The hash method in JDK 1.8 is simplified compared to the hash method in JDK 1.7, but the principle remains unchanged.
static final int hash(Object key) {
int h;
// key.hashCode(): returns hash value also known as hashcode
// ^: bitwise XOR
// >>>: unsigned right shift, ignoring the sign bit, filling the empty bits with 0
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Let’s compare this with the hash method source code in JDK 1.7.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}Compared to the hash method in JDK 1.8, the hash method in JDK 1.7 is somewhat less efficient because it performs perturbation 4 times.
The so-called "chaining method" combines linked lists and arrays, creating an array of linked lists. When a hash collision occurs, the colliding value is simply added to the linked list.
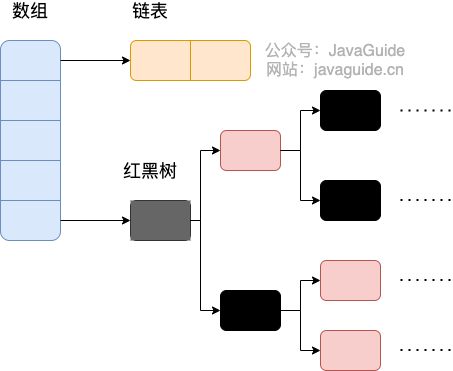
After JDK 1.8, there were significant changes in how hash collisions are resolved compared to previous versions.
When the length of the linked list exceeds the threshold (default is 8), the method treeifyBin() will be called first. This method decides whether to convert the structure into a red-black tree based on the HashMap array. The conversion to a red-black tree will only occur when the array length is greater than or equal to 64, in order to reduce search time. Otherwise, it will simply call the resize() method to expand the array. The relevant source code will not be included here; the focus should be on the treeifyBin() method!
Class Properties:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// Serial number
private static final long serialVersionUID = 362498820763181265L;
// Default initial capacity is 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// Maximum capacity
static final int MAXIMUM_CAPACITY = 1 << 30;
// Default load factor
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// Threshold for converting to red-black tree
static final int TREEIFY_THRESHOLD = 8;
// Threshold for converting tree back to linked list
static final int UNTREEIFY_THRESHOLD = 6;
// Minimum capacity for converting bucket structure to red-black tree
static final int MIN_TREEIFY_CAPACITY = 64;
// Array for storing elements, always a power of 2
transient Node<K,V>[] table;
// A view of the collection containing all key-value pairs in the map
transient Set<Map.Entry<K,V>> entrySet;
// Count of elements stored; note this is not equal to the length of the array.
transient int size;
// Counter for each expansion and structural change to the map
transient int modCount;
// Threshold (capacity * load factor); when actual size exceeds this threshold, resizing occurs
int threshold;
// Load factor
final float loadFactor;
}-
Load Factor
The load factor controls the density of the data stored in the array. The closer the load factor is to 1, the more items (entries) the array can hold, and the denser the storage becomes, which increases the length of lists. Conversely, a smaller load factor, nearing 0, results in sparser data storage with fewer items.
A load factor that is too large can reduce search efficiency, while a load factor that is too small can lead to low array utilization and widespread storage. The default value of 0.75f provides a balanced threshold recommended by the official documentation.
Given the default capacity of 16 and the load factor of 0.75, as data is stored and exceeds the limit of 16 * 0.75 = 12, an expansion of the current 16 capacity is needed, which involves operations like rehashing and data copying, potentially consuming a lot of performance.
-
Threshold
Threshold = capacity * load factor. When size > threshold, it indicates that the array requires an increase in size, thus serving as a criterion for measuring the need for an array expansion.
Node Class Source Code:
// Inherits from Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; // Hash value to compare with other elements when storing in hashmap
final K key; // Key
V value; // Value
// Points to the next node
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// Override hashCode() method
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// Override equals() method
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}Tree Node Class Source Code:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // Parent
TreeNode<K,V> left; // Left
TreeNode<K,V> right; // Right
TreeNode<K,V> prev; // Needed to unlink next upon deletion
boolean red; // Indicates color
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// Returns the root node
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}HashMap has four constructors, which are as follows:
// Default constructor.
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// Constructor with another "Map"
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false); // this method will be analyzed later
}
// Constructor specifying "initial capacity"
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// Constructor specifying "initial capacity" and "load factor"
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
// Store initial capacity temporarily in threshold; assign to newCap for table initialization during resize
this.threshold = tableSizeFor(initialCapacity);
}It is worth noting that all four constructors initialize the load factor. Since HashMap does not have a field like capacity, even if an initial capacity is specified, it is rounded to the nearest power of 2 in
tableSizeForand temporarily assigned to threshold, which is later assigned to newCap for table initialization in the resize method.
putMapEntries Method:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// Check if table has already been initialized
if (table == null) { // pre-size
/*
* Not initialized; s is the actual number of elements in m.
* ft=s/loadFactor => s=ft*loadFactor, which resembles the concept
* threshold=capacity*loadFactor.
* ft represents the minimum capacity required to add s elements.
*/
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
/*
* According to the constructor, the table has not been initialized.
* If the minimum capacity required to add s elements exceeds the initialized capacity,
* then the minimum capacity is expanded to the nearest power of 2 as the initialization.
* Note this is not the initialization threshold.
*/
if (t > threshold)
threshold = tableSizeFor(t);
}
// Initialized, and element count in m exceeds threshold; proceed with resize
else if (s > threshold)
resize();
// Add all elements from m to HashMap; if table is uninitialized, putVal will call resize to initialize or expand
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}HashMap only provides the put method for adding elements; the putVal method is called by put and is not exposed to users.
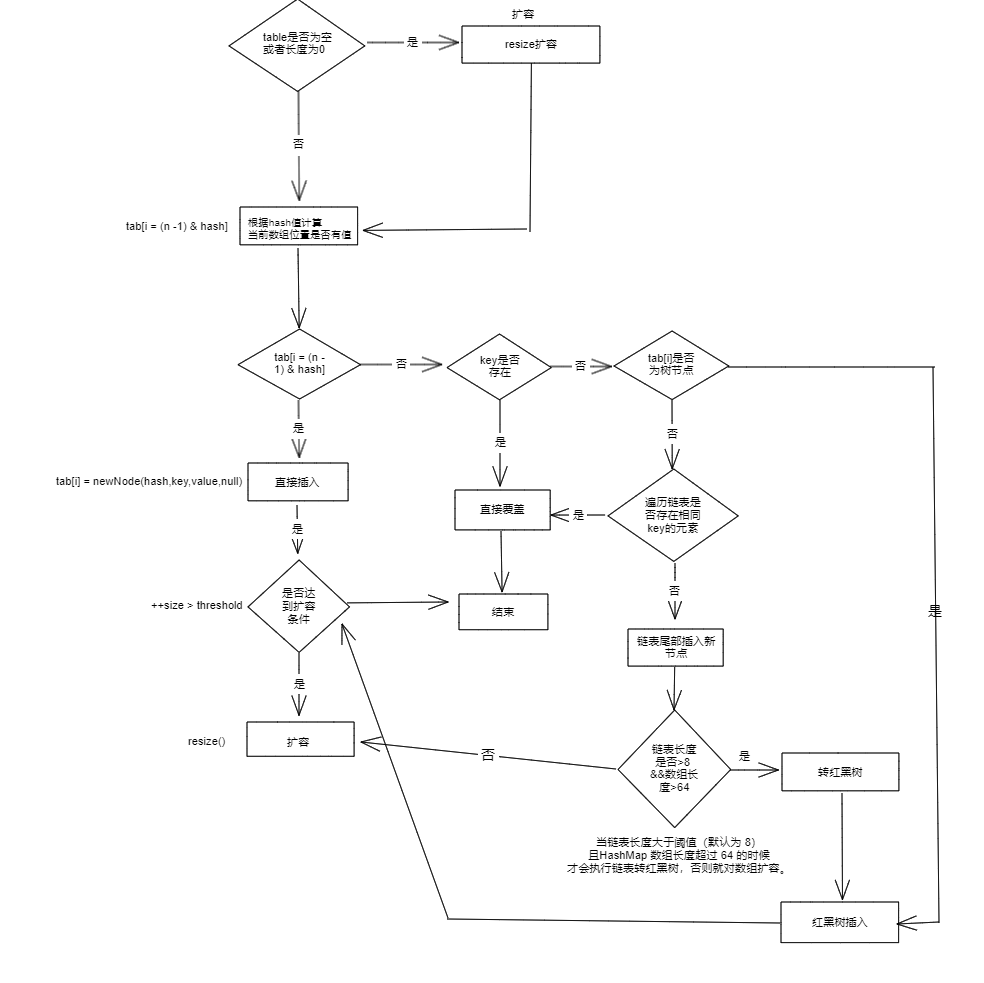
Analysis of adding elements through the putVal method:
- If the located array position is empty, it is inserted directly.
- If there is already an element positioned at the array location, it will compare with the key to be inserted. If the keys are the same, it will directly overwrite; if the keys are different, it checks if p is a tree node, and if so, calls
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)to add the element. If it is not, it iterates through the linked list to insert (at the end of the linked list).
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// If table is uninitialized or length is 0, expand
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash determines which bucket to store the element in.
// If that bucket is empty, create a new node and store it there (initially, this will add the node to the array)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// If the bucket already has an element (handle hash collisions)
else {
Node<K,V> e; K k;
// Quickly check if the first node table[i] has a key the same as the key being inserted; if so, replace the old value with the new value p directly.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// Check if the inserted node is a red-black tree node
else if (p instanceof TreeNode)
// Insert into the tree
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// If not a red-black tree node, it is a linked list node
else {
// Insert the node at the tail of the linked list
for (int binCount = 0; ; ++binCount) {
// Reached the end of the linked list
if ((e = p.next) == null) {
// Insert new node at the end
p.next = newNode(hash, key, value, null);
// If the count of nodes reaches the threshold (default is 8), execute treeifyBin method
// This method will determine whether to convert to a red-black tree based on the HashMap array.
// A conversion to a red-black tree will only occur if the array length is greater than or equal to 64 to reduce search time; otherwise, just expand the array.
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// Break the loop
break;
}
// Compare the key value of the node in the linked list with the key value of the incoming element
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// If equal, break the loop
break;
// This is used to traverse the linked list; combined with the previous e = p.next, it can traverse the linked list
p = e;
}
}
// Indicates that a node with the key value and hash value equal to the inserted element was found in the bucket
if (e != null) {
// Store the value of e
V oldValue = e.value;
// onlyIfAbsent is false or old value is null
if (!onlyIfAbsent || oldValue == null)
// Replace the old value with the new value
e.value = value;
// Callback after access
afterNodeAccess(e);
// Return the old value
return oldValue;
}
}
// Structural modification
++modCount;
// If actual size exceeds threshold, resize
if (++size > threshold)
resize();
// Callback after insertion
afterNodeInsertion(evict);
return null;
}Let’s compare the put method code in JDK1.7.
Analysis of the put method is as follows:
- ① If the located array position is empty, it is inserted directly.
- ② If there is already an element located at the array position, traverse the linked list with that element as the head node, comparing it sequentially with the key being inserted; if the keys are the same, it directly replaces it; if not, the insertion is done using a head insert method.
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // first traversal
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // Insert afterwards
return null;
}public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Array elements are equal
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// More than one node in the bucket
if ((e = first.next) != null) {
// Get in the tree
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// Get in the linked list
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}Expansion will be accompanied by a rehash allocation and a traversal of all elements in the hash table, which is very time-consuming. In programming, it is advisable to avoid using resize. The resize method actually integrates table initialization with table expansion, where the underlying behavior is to assign a new array to the table.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// If exceeding the maximum size, do not expand further, let collisions occur
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// Not exceeding the maximum size, expand to double the original size
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
// When creating an object, initialize capacity; at this point just take it as the new array capacity
newCap = oldThr;
else {
// signifies using defaults No-arg constructor creates an object with calculated capacity and threshold here
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
// Presumably specified initialization capacity or load factor, initializing threshold here,
// or the old capacity was less than 16, calculating the new resize upper limit
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Move each bucket to the new buckets
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
// Only one node; directly calculate the new position for the element
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// Split the red-black tree into two subtrees, if the node count of the subtree is less than or equal to UNTREEIFY_THRESHOLD (default 6), convert the subtree into a linked list.
// If the node count of the subtree exceeds UNTREEIFY_THRESHOLD, maintain the tree structure of the subtree.
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Original index
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Original index + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Place original index in bucket
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Place original index + oldCap in the bucket
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}package map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
// Keys cannot be repeated, values can be repeated
map.put("san", "Zhang San");
map.put("si", "Li Si");
map.put("wu", "Wang Wu");
map.put("wang", "Old Wang");
map.put("wang", "Old Wang 2");// Old Wang is overwritten
map.put("lao", "Old Wang");
System.out.println("-------Direct Output of HashMap:-------");
System.out.println(map);
/**
* Traverse HashMap
*/
// 1. Get all keys in the Map
System.out.println("-------foreach to get all keys in the Map:------");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.print(key + " ");
}
System.out.println();// New line
// 2. Get all values in the Map
System.out.println("-------foreach to get all values in the Map:------");
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value + " ");
}
System.out.println();// New line
// 3. Get the value corresponding to the key along with the key
System.out.println("-------Get the value corresponding to the key along with the key:-------");
Set<String> keys2 = map.keySet();
for (String key : keys2) {
System.out.print(key + ":" + map.get(key) + " ");
}
/**
* If you need to traverse both keys and values, this method is recommended,
* because if you first get the keySet and then execute map.get(key),
* there will be two traversals internally by the map.
* One to get the keySet, and one while traversing all keys.
*/
// When I call put(key,value), the key and value are first encapsulated into
// an Entry static inner class object, which is then added to the array,
// so to get all key-value pairs in the map,
// we need to get all Entry objects in the array,
// then call Entry object's getKey() and getValue() methods to retrieve the key-value pairs.
Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
/**
* Other commonly used methods of HashMap
*/
System.out.println("after map.size():" + map.size());
System.out.println("after map.isEmpty():" + map.isEmpty());
System.out.println(map.remove("san"));
System.out.println("after map.remove():" + map);
System.out.println("after map.get(si):" + map.get("si"));
System.out.println("after map.containsKey(si):" + map.containsKey("si"));
System.out.println("after containsValue(李四):" + map.containsValue("李四"));
System.out.println(map.replace("si", "Li Si 2"));
System.out.println("after map.replace(si, Li Si 2):" + map);
}
}