Description
为什么分享动态规划
不正经原因:
-
看看能不能装个逼
-
大厂面试都会考算法,通过这次分享,争取向各个大厂输送一点多点人才,不管是二进宫还是三进宫
正经原因:
实习的时候,听到一个后端讲:“前端?屁算法不懂!”,当时我看见我的导师破防了,坐在椅子上泣不成声。那一刻我就在想,如果我学会了算法,我一定要赢下所有。
如今,我的算法分享就在眼前,在座的各位必须考虑这会不会是你此生仅有的机会学会动态规划
1. 什么是动态规划?
dynamic programming is a method for solving a complex problem by breaking it down into a collection of simpler subproblems,
solving each of those subproblems just once,
and storing their solutions.
动态规划是一种数学优化方法。从考试/竞赛/面试的角度看时,通常视作一个算法,常用于解决最优解问题。
上面的英文释义看起来有点像分治算法:都是把大问题拆分成小问题,但是区别在于:
- 分治算法拆解出的子问题往往相互独立,且没有重复子问题
- 动态规划拆解出的子问题存在一定关联,更强调子问题只会被解决一次,并且会被存储。
1.1 动态规划的特点
动态规划可解问题满足以下三个特点:
- 存在最优子结构:子问题的最优解可以推导出全局最优解
- 存在重复子问题:存在同一个子问题会被求解多次的场景,比如用递归的时候总是会出现
- 无后效性:走不同的道,最后到达了同一个状态,而后续的状态变迁都是一样的,那么之前走了什么路,都没有关系,对后半部分没有影响
这部分不理解没关系,后面例题中会提到
2. 题目一:斐波那契数列 (leetcode 509)
斐波那契数列既是一道经典的递归入门题目,也可以是一道经典的动态规划入门题目,虽然它不是严格意义上的动态规划
排除通项公式、矩阵快速幂数学解法(因为在座的各位数学水平应该回滚到了初中水平)、排除掉调用内置函数的解法,接下来会提到四种解法:
- 递归
- 记忆化递归
- 动态规划
- 动态规划滚动数组优化
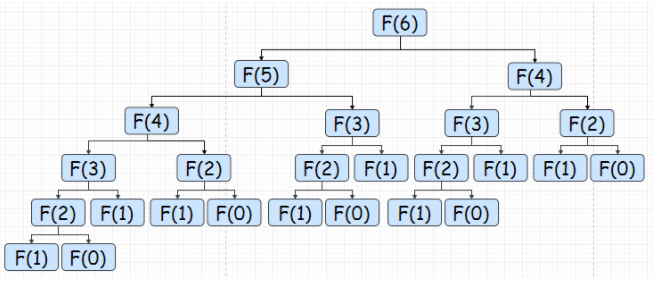
2.1 递归解法:自顶向下
时间复杂度 O(2^n):数一数有多少个蓝色节点即可
空间复杂度 O(n):栈的深度,这里不考虑尾递归优化
重复计算太多,这里重复计算的众多节点,就是上面提到的重复子问题,代码略
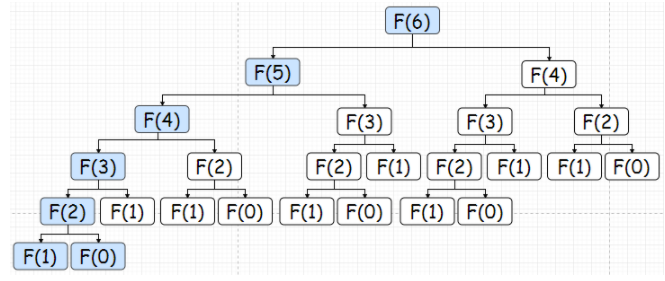
2.2 记忆化递归:自顶向下
容易想到,用O(n)的空间存储计算过的结果,代码略
时间复杂度:降到 O(n)
空间复杂度:开辟 O(n) 空间 + O(n)栈空间 = O(n)
2.3 动态规划:自底向上
既然知道 fib(0) = 0, fib(1) = 1, fib(n) = fib(n - 1) + fib(n - 2), 从底部向上推导即可
时间复杂度:O(n)
空间复杂度:O(n)
const fib = n => {
const dp = [0, 1]
for (let i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2]
}
return dp[n]
}2.4 动态规划滚动数组优化
因为状态转移方程:dp[n] = dp[n-1] + dp[n-2],在计算下一个状态时,只用到了当前值和前一个值,自然可以用两个变量优化,然后这么滚动下去。
时间复杂度:O(n)
空间复杂度:O(1)
const fib = n => {
let a = 0, b = 1
for (let i = 2; i <= n; i++) {
[a, b] = [b, a + b]
}
return b
}(不明白没关系,后面有更详细的解释)
2.5 本题小结
fib的例子可以很好的说明什么是重复子问题。- 递归和动态规划明显的差异点就是:前者是自顶向下,后者是自底向上。
- 为什么说斐波那契是列不是严格意义上的动态规划:简单理解就是因为最优子结构,无后效性的概念套不上去。
3. 题目二:零钱兑换easy版 (leetcode 322改)
假设您是个土豪,身上带了足够的1、5、10、20、50、100元面值的钞票。现在您的目标是凑出某个金额w,需要用到尽量少的钞票,你会怎么做?
生活中的经验是:能用100的就尽量用100的,否则尽量用50的……依次类推
实际情况表明。这个做法准确无误。这个策略就是贪心策略,不过贪心策略会一直管用吗?
3.1 一点题外话,激活一下大家
写这个部分的时候看到知乎的一条评论

然后检索了一下贪心算法和货币面值的信息:
有远古时期的题目
有用三元人民币打脸的

最后结论是:能满足贪心性质的货币面值组合有不少,1、5、10...这种组合更贴近使用习惯
3.2 真实的第二题
有无限多的1、5、11元面值的钞票。现在您的目标是凑出某个金额w,求需要的最小张数。
从贪心算法的角度来凑出 15 元:首先取出 1 张 11 元,然后取出 4 张 1 元,共计 5 张
而最优解只需要 5 + 5 + 5,共计三张
因为贪心策略的纲领是:尽量使接下来面对的w更小,因此第一步会将w降到4,而凑出4的代价是很高的,这样就显得鼠目寸光
3.3 动态规划求解
题目需要求出:凑出某个金额w,需要的最小张数
不妨设:dp[n]为凑出金额n所需要的最小张数
显然,还可以获得一些初始值:
dp[1] = 1:凑1元的最优解是一张1元dp[5] = 1:凑5元的最优解是一张5元dp[11] = 1:凑11元的最优解是一张11元
由于目前只有1,5,11三种面值,所以对于dp[15]来说,第一步只有这三种取钱方案,而由于dp定义,这三个里一定有一个是答案
- 取11:
dp[15] = dp[4] + 1 = 5 - 取5:
dp[15] = dp[10] + 1 = 3(最优) - 取1:
dp[15] = dp[14] + 1 = 5
非常容易观察出,dp[n]的结果只与dp[n-1]、dp[n-5]、dp[n-11]有关,确切的说:
dp[n] = min( dp[n-1], dp[n-5], dp[n-11] ) + 1
所以实现如下:
function coins(n) {
const dp = new Array(n + 1).fill(Number.MAX_VALUE)
dp[0] = 0
dp[1] = 1
dp[5] = 1
dp[11] = 1
for (let i = 2; i <= n; i++) {
dp[i] = Math.min(dp[i], dp[i - 1] + 1)
if (i >= 5) dp[i] = Math.min(dp[i], dp[i - 5] + 1)
if (i >= 11) dp[i] = Math.min( dp[i], dp[i - 11] + 1)
}
return dp[n]
}3.4 本题小结
贪心算法每个阶段都选择最优解,那么最后自然也是最优解的前提是:每个阶段的选择不影响后面的选择
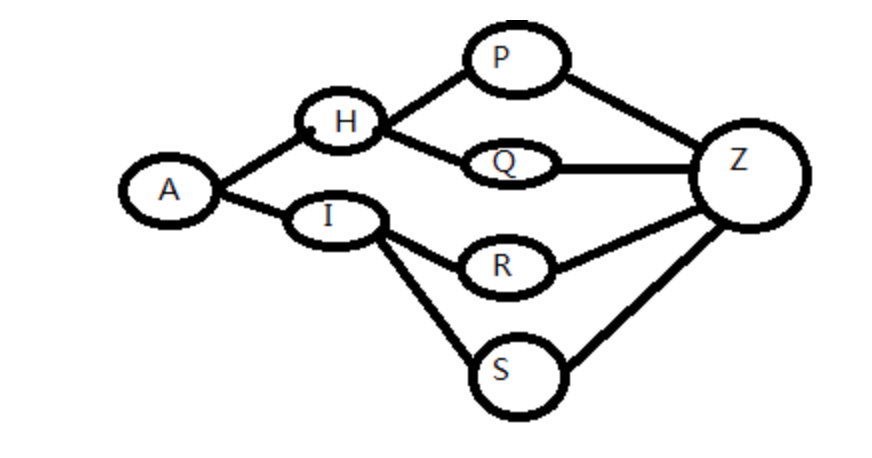
例如下图中,第一步可以选择H / I, 选择了之后并不影响我后面还能够选择 P / Q,所以步步最优 = 结果最优
贪心选择性:通过局部最优的选择,能产生全局的最优选择
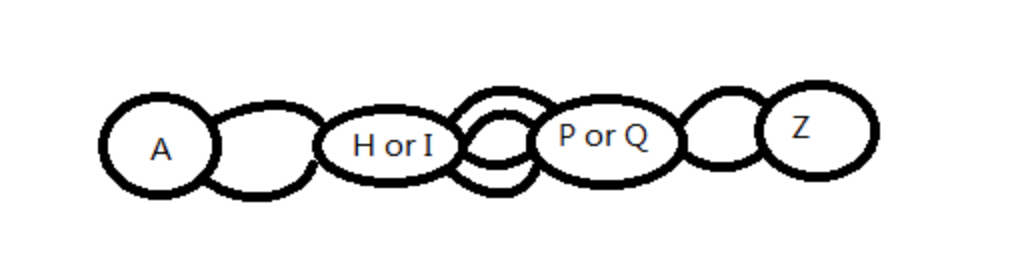
而这个图中,第一步选择后,后面的路已经不同了,我能保证第一步最优,但无法保证结果最优,这个图的最优路径肯定要都走一遍才能确定(穷举)
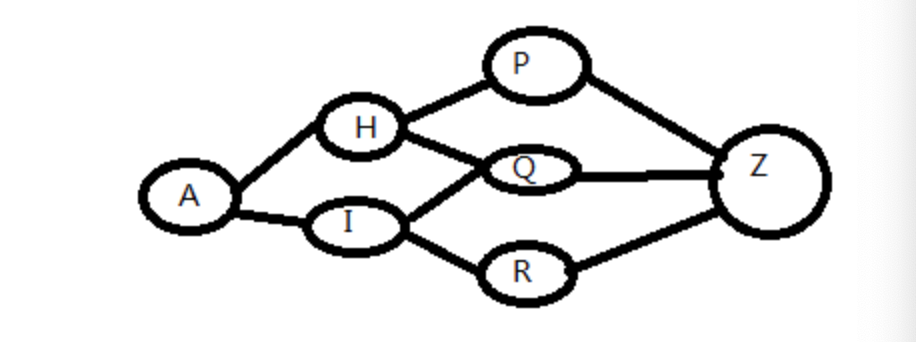
再看这个图,由于Q的入度是2,是一个状态交点,那么如果我知道到Q的最优解,对于后面的过程来说,计算一个最终最优解,根本不关心是走的AHQ,还是AIQ(这也是无后效性的一个体现)
4. 题目三:不同路径(leetcode62)
这道题是许多矩阵型动态规划题目的基础版本,通过此题,我们可以:
- 展示一个二维DP问题的正常解答流程
- 展示动态规划滚动数组优化的实现

4.1 寻常动态规划求解过程
- 定义
dp数组的含义:设dp[i][j]为从左上角走到(i, j)的路径数量 - 思考状态转移方程:因为每一步只能向下或者向右移动,那么
dp[i][j]的解为:dp[i][j] = dp[i - 1][j] + dp[i][j - 1](i >= 1 , j >= 1) - 寻找初始值:
dp[i][0]都等于 1,dp[0][j]都等于 1 - 最后需要返回什么:返回
dp[m-1][n-1]
因此,时间复杂度为O(mn),空间复杂度为O(mn)的动态规划解如下:
function uniquePaths(m, n) {
// 初始化二维dp数组
const dp = new Array(m).fill(0).map(() => new Array(n).fill(0))
// 填充初始值
for (let i = 0; i < m; i++) {
dp[i][0] = 1
}
for (let j = 0; j < n; j++) {
dp[0][j] = 1
}
// 遍历可能解空间
for (let i = 1; i < m; i++) {
for (let j = 1; j < n; j++) {
dp[i][j] = dp[i - 1][j] + dp[i][j - 1]
}
}
return dp[m - 1][n - 1]
}4.2 滚动数组优化
滚动数组优化在上文的斐波那契数列中提到过,将O(n)的空间优化到了O(1),在二维DP问题中,通常可以将O(mn)的空间复杂度优化到O(min(m, n))
那么为什么存在滚动数组优化:在DP过程中,我们由一个状态转向另一个状态时,很可能之前存储的某些状态信息就已经无用了
比如第一题中的滚动数组优化:
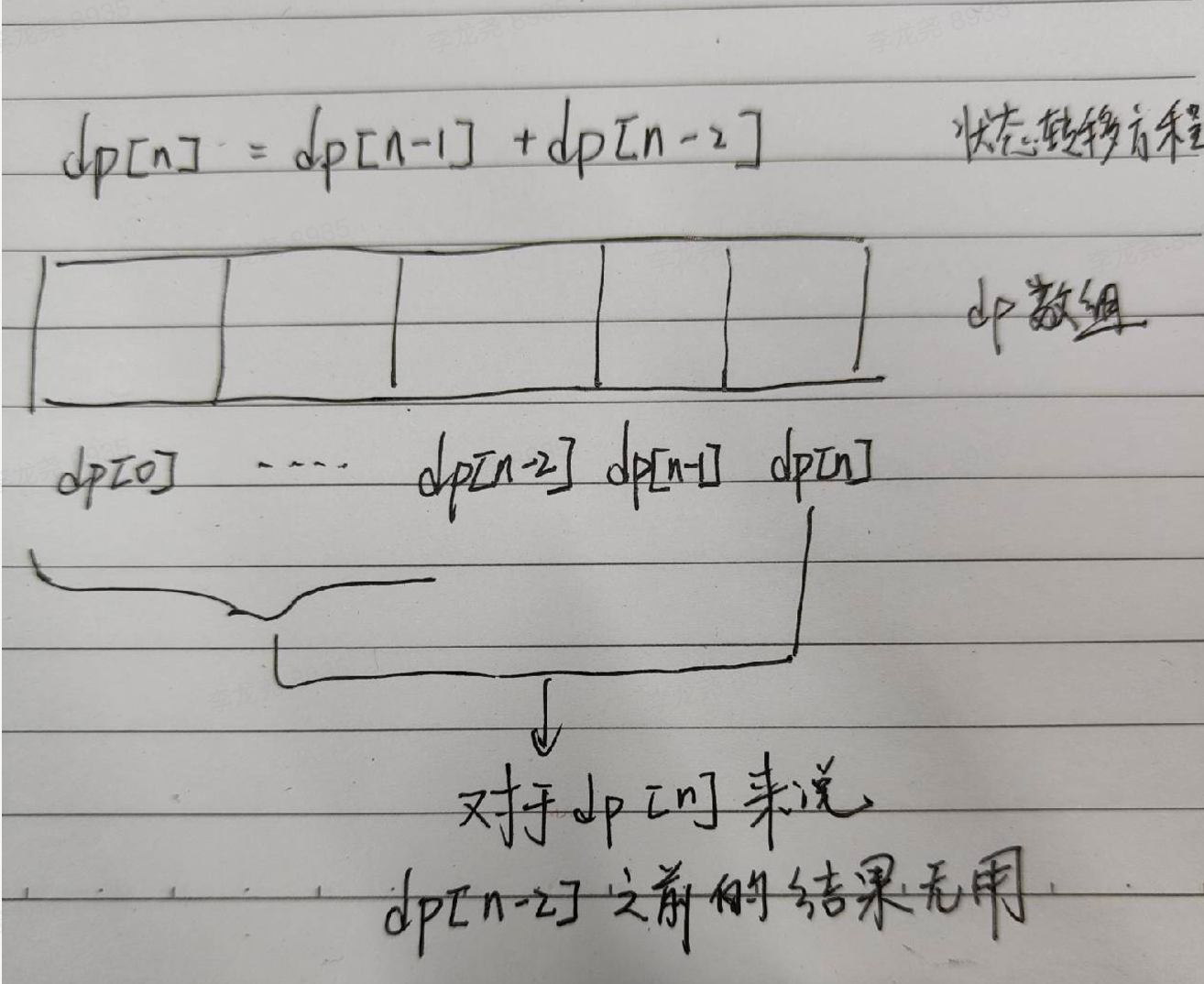
本题的滚动数组优化解释:

解答:
function uniquePaths(m, n) {
// 使得n最小
if (n > m) {
[m, n] = [n, m]
}
// 初始化一维dp数组并填充初始值
const dp = new Array(n).fill(1)
dp[0] = 1
// 遍历可能解空间
for (let i = 1; i < m; i++) {
for (let j = 1; j < n; j++) {
dp[j] = dp[j] + dp[j - 1]
}
}
return dp[n - 1]
}对比:
5. 动态规划与其他算法的对比小结
关于动态规划核心的三要素:
- 最优子结构
- 重复子问题
- 无后效性
这三要素并不是动态规划专有的,结合贪心算法、递归算法、回溯算法、分治算法来看一下:
- 分治算法:拆分成子问题,子问题之间无关联,不存在重复子问题(联想阮一峰版的快速排序实现)
- 递归算法:存在重复子问题,因此会有记忆化递归(斐波那契数列例子)
- 回溯算法:理解为穷举,存在重复子问题,结合剪枝,也就比暴力好一点
- 贪心算法:存在最优子结构、存在无后效性以及贪心选择性(凑硬币例子)