Description
Hey everyone!
After more than 2 years being blocked, PR #302 was merged just two weeks ago. It purportedly fixes issues were queries were being wrongly "retried" (i.e. being ran twice by the database/sql client even though the original query went through). To accomplish this, it reduces the number of places where the driver returns a driver.ErrBadConn error: it only returns this value when we're 100% sure that the database has not received the original query, as returning ErrBadConn forces the database/sql client to retry the query altogether with a different connection, hence leading to redundant/repeated queries.
In practice, however, this breaks the driver in any situation where the MySQL server can kill connections on the server side. Let's analyse why and try to find a workaround for this issue.
Reproduction
We're gonna make the driver crash with a pretty simple reproduction recipe.
First, we need a MySQL server configured to timeout idle connections. We're gonna use MySQL 5.7 and simply set global wait_timeout=3;. This will make mysqld kill any connections that haven't been active (i.e. sending queries) for 3 seconds. This whole example also works with any maintained MySQL release, including 5.6, and all MariaDB releases. The 3 second timeout is a bit aggressive but it's something similar to what we run in our main MySQL cluster here at GitHub.
With this MySQL server in place, we can reproduce the issue with a few lines of Go code, using the master branch of go-sql-driver/mysql:
db, err := sql.Open("mysql", dsn)
assert.NoError(t, err)
defer db.Close()
assert.NoError(t, db.Ping())
// Wait for 5 seconds. This should be enough to timeout the conn, since `wait_timeout` is 3s
time.Sleep(5 * time.Second)
// Simply attempt to begin a transaction
tx, err := db.Begin()
assert.NoError(t, err)The result of pinging the DB, sleeping for 5 seconds, then attempting to begin a transaction, is a crash:
Error: Received unexpected error: invalid connection
It is clear that this is not the right behaviour. The mysqld instance is still up throughout the test, so even if the initial connection got killed by the server, calling db.Begin() should create a new connection instead of returning an error. This was the behaviour before #302 was merged.
So, what's the underlying issue here, and why is database/sql not retrying the connection after the changes in #302?
Deep Dive
The changes in #302 are sensible and appear correct when reviewed. The "most important" modification happens in packets.go, in the code to handle writes:
Lines 121 to 147 in 26471af
The PR adds line 140, where if n == 0 && pktLen == len(data)-4 is checked. The rationale is as follows:
-
Any interaction (i.e.
query,exec) from the driver to the MySQL server happens in two phases: First, we write the packet with the query/exec command to the socket connected to the server. If this write succeeds, it means the server must write back an "answer" packet, so we immediately read the response from the socket. -
If this write doesn't succeed, it means the connection has gone bad (maybe the server killed it?), but we know for sure the server has not received our query, so we can return
errBadConnNoWrite, which will get translated down the driver intodriver.ErrBadConnand forcedatabase/sqlto retry the query with another connection. -
However: If the write succeeds but the follow-up read from the socket fails (i.e. we never receive the "answer packet" from MySQL), we cannot return
ErrBadConn, because the server has received our query and may have executed it even though we received no answer. We cannot letdatabase/sqlretry this query.
This is perfectly sensible, but the previous reproduction recipe shows it doesn't work in practice. In our code, the following sequence of actions happens:
- We connect to the MySQL server.
sql.Open - We ping the MySQL server by sending a "ping" packet
- We receive a "pong" packet response from MySQL --
db.Pingreturns successfully - We sleep for 5 seconds
- After just 3 seconds, the MySQL server is going to kill our driver's only open connection
- We wake up from sleep and attempt to begin a transaction, by
execing aSTART TRANSACTION. - We write an
execpacket to the server withSTART TRANSACTION. The write succeeds - We then read the response packet from MySQL: This read fails, because MySQL killed our connection -- but now the driver cannot return
ErrBadConnto retry this operation, because our initial write succeeded! The server may have executedSTART TRANSACTION! So the driver's only option is to hard crash.
When written like this, the problem becomes really clear. #302 made an assumption about the TCP protocol that doesn't hold in practice: that after MySQL server has killed our connection, trying to write a packet from the driver to the server will return an error. That's not how TCP works: let us prove it by looking at some packet captures. 😄
This are steps 1 through 8 seen through Wireshark:
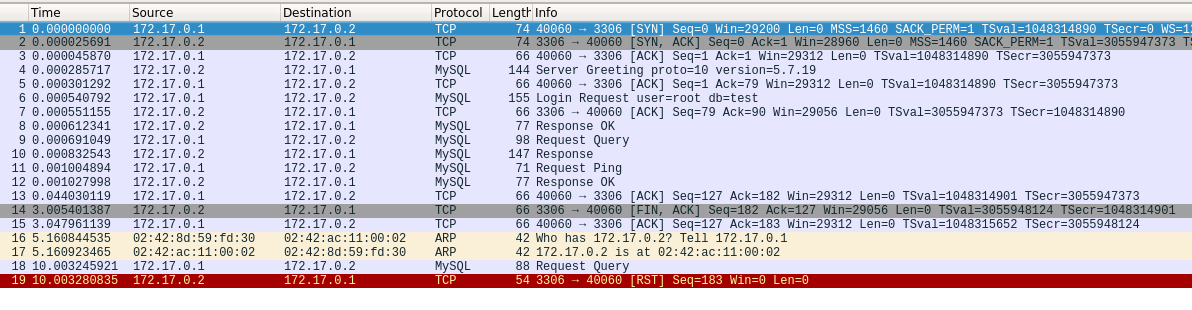
The beginning is straightforward. We open the connection with a TCP handshake, we send a ping packet and we get a reply back (you can actually see two pings + two replies in that capture). We then go to sleep.
...And just 3 seconds later, in frame 14, the MySQL server enacts the timeout we've configured. Our TCP connection gets closed on the server side and we receive a [FIN, ACK] pair... To which our Golang client simply responds with an ACK! There's no FIN response from the driver because we haven't closed our side of the connection, as we're sleeping.
Seven seconds later, at T+10 (frame 18), we wake up from our sleep and attempt to exec a START TRANSACTION. And (here's what throws us off), the Linux kernel accepts the write just fine. It returns no error to Golang, because this is how TCP works. TCP is a bidirectional protocol, and our side of the connection is still open, so the write goes through.
Of course, the MySQL server immediately replies -- with a RST. "Dude, this connection is over". But it's too late for our driver: the write of the exec packet already succeeded, and with this new logic, we assume that the query may have been executed by the server (even though the MySQL server was not even listening on our socket anymore).
And meanwhile, the kernel has received the RST packet from the MySQL server. The next time we attempt to read from our connection, we will definitely crash. But with this new logic, a retry won't be attempted! This is bad news, because our original exec was not even close to making it to the server -- let alone being executed.
What are the potential fixes?
There is, in theory, a "right way" to handle this general case of the server closing a connection on us: performing a zero-size read from the socket right before we attempt to write our query packet should let us know about that FIN packet we've received: "MySQL has closed this connection, buddy. Your side is open, so you can still write, and the kernel will swallow it... But it's pointless because MySQL isn't reading anymore and -- even if it were --, the FIN means it wouldn't be able to reply".
Here's the issue: the "zero read" semantics from Golang are a bit fuzzy right now. This commit from bradfitz special-cases this situation so the read never makes it to the kernel; before that, the read would always return io.EOF.
This closed issue in golang/go has a very similar analysis to this one (at the TCP level -- not really related to MySQL), with several Golang core devs chiming in.
Ian Lance Taylor comments:
I don't see what Go can do here. Try using "go test -c" to build your test into an executable and then run "strace -f EXECUTABLE". You will see that the final write system call succeeds and the kernel reports it as succeeding. Go is just returning that success to the caller. The same thing would happen for a C program.
At the TCP level, you have closed one side of the TCP connection but not the other. The kernel will accept writes until both sides are closed. This is not as simple a matter as you seem to be expecting. I found a decent description of the issue at http://stackoverflow.com/questions/11436013/writing-to-a-closed-local-tcp-socket-not-failing .
The "final write system call" that Ian talks about here is the same as our "trying to write START TRANSACTION after our sleep, and indeed, it succeeds at the kernel level.
Brad Fitzpatrick wraps up the issue with a comment on zero-size reads from Golang:
FWIW, the 0-byte-Read-always-returns-EOF was changed in Go 1.7 with 5bcdd63. But as of Go 1.7 it now always returns nil, which is at least a bit more Go-like, but still doesn't tell you whether FIN was ever seen arriving. There aren't great APIs anywhere (especially not portably) to know that without reading data.
Another still open issue in golang/go explains why is there --still-- no way to see if the socket is good for reading (and hence it makes sense writing to it).
In Conclusion
I hope this in-depth analysis wasn't too boring, and I also hope it serves as definitive proof that the concerns that some people (@xaprb, @julienschmidt) had on the original PR are indeed very real: we tried rolling out the master branch of this driver in one of our Golang services and it's unusable with any of our MySQL clusters here at GitHub.
As for a conclusive fix: I honestly have no idea. I would start by reverting the PR; I think the risk of duplicated queries is worrisome, but the driver as it is right now is unusable for large MySQL clusters that run tight on connections and do pruning.
Doing a Ping before attempting new queries on connections that could be "stale" seems like a feasible workaround. But how do we mark such connections as stale? What's the timeframe? Should we let the users configure it? What's the overhead going to be like?
I would love to hear from the maintainers on approaches to fix this. I have time and obviously interest on using the master branch of this driver in production and I'll gladly write & PR any fix for this issue that you deem acceptable.
Cheers!